

今回は外部データの処理をしやすくなるライブラリ「Pandas」を紹介するよ!


「外部データ」ってどんなデータなの?
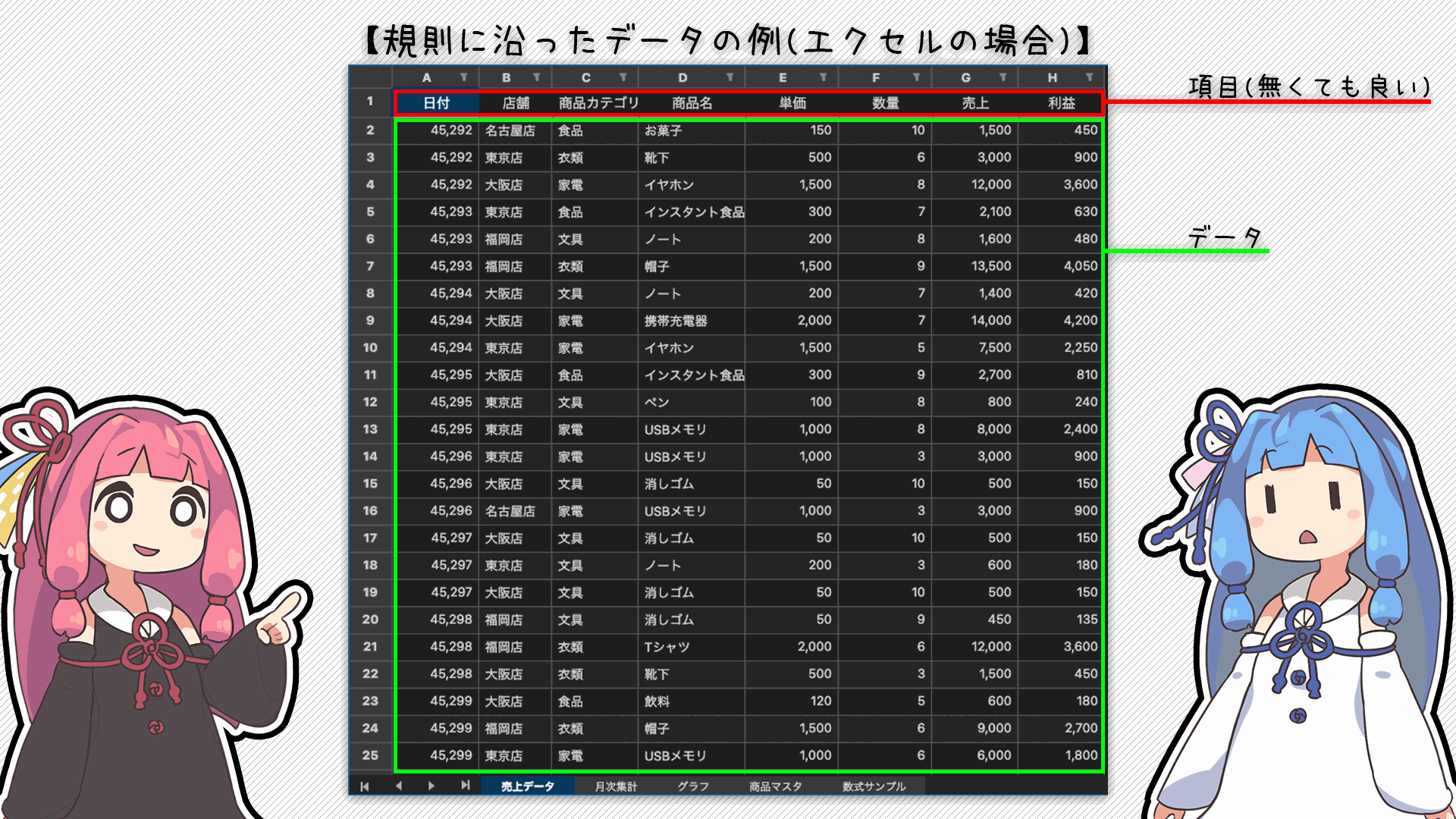
ここでいう「外部データ」は「行と列がある表のようなデータ」のことで、データベースやエクセル、JSONとかで管理されていればPandasで扱えるよ
エクセルとJSONは前に出てきてるから分かるけど、「データベース」ってなに??
データベースは沢山のデータを整理・保存して、すばやく取り出せるようにしたしくみのことで、まぁエクセルで管理するのと似たようなものだと思っておけば良いかな?
なるほど
Pandasでファイルを読み込む場合は「pd.read_〇〇('ファイル名')」で出来て、逆に書き込みたい時は「pd.to_〇〇('ファイル名')」で出来るよ!
今回はエクセルファイルを読み込む場合のプログラム例を見せるね
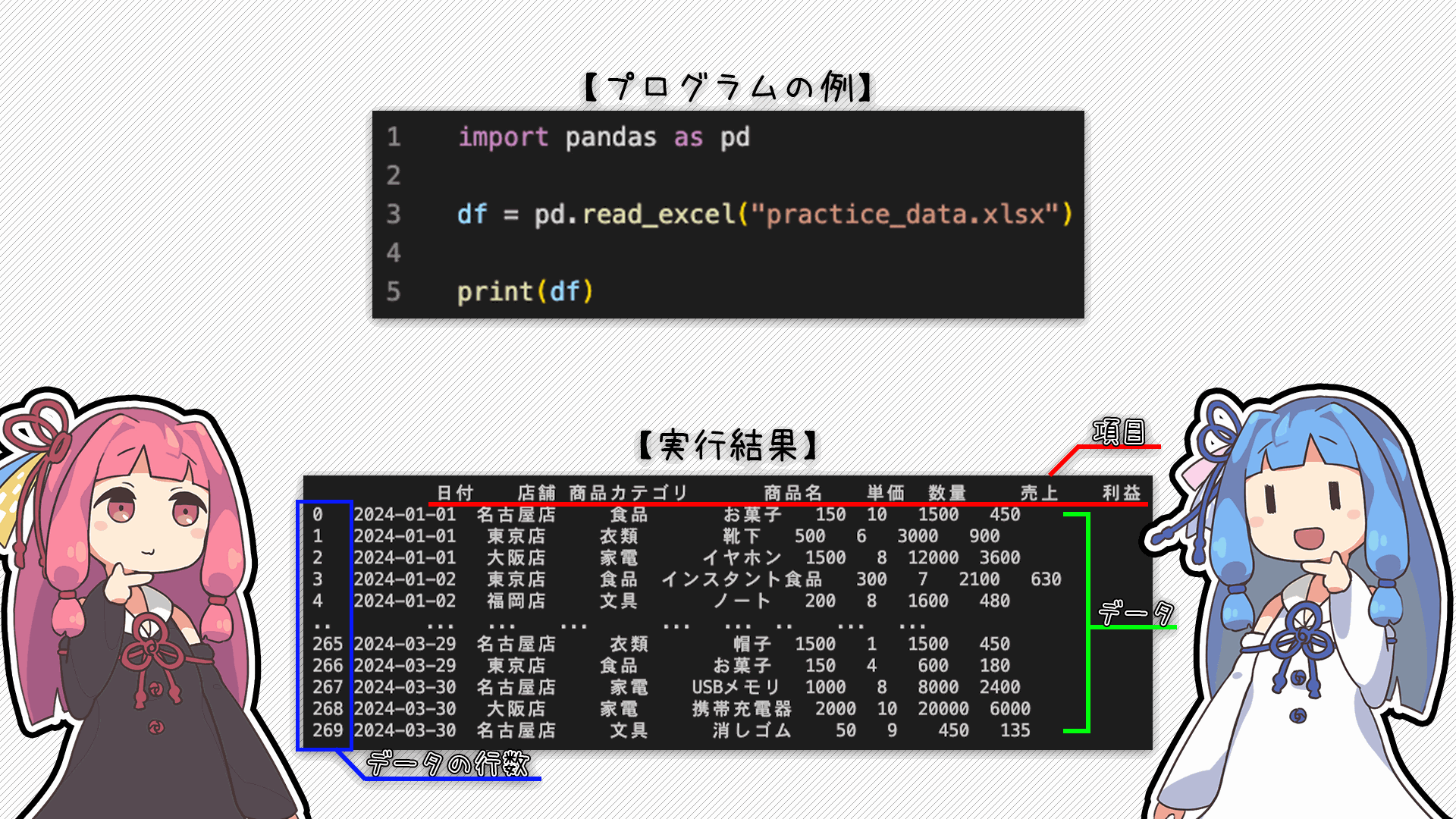
なんかいつもと違う感じで表示されるね
Pandasでは「DataFrame型」っていうデータ型で管理されるからね!
エクセルの場合、1行目が項目として扱われて、それ以降がデータとして管理されるよ!
んで、これはどうやって使うことになるの??
今回は3つの簡単な使い方を紹介するね!
まずは指定した項目の中で特定のデータだけを取り出す方法を紹介するね
「店舗」の項目のうち、「名古屋店」の情報だけを取り出すよ
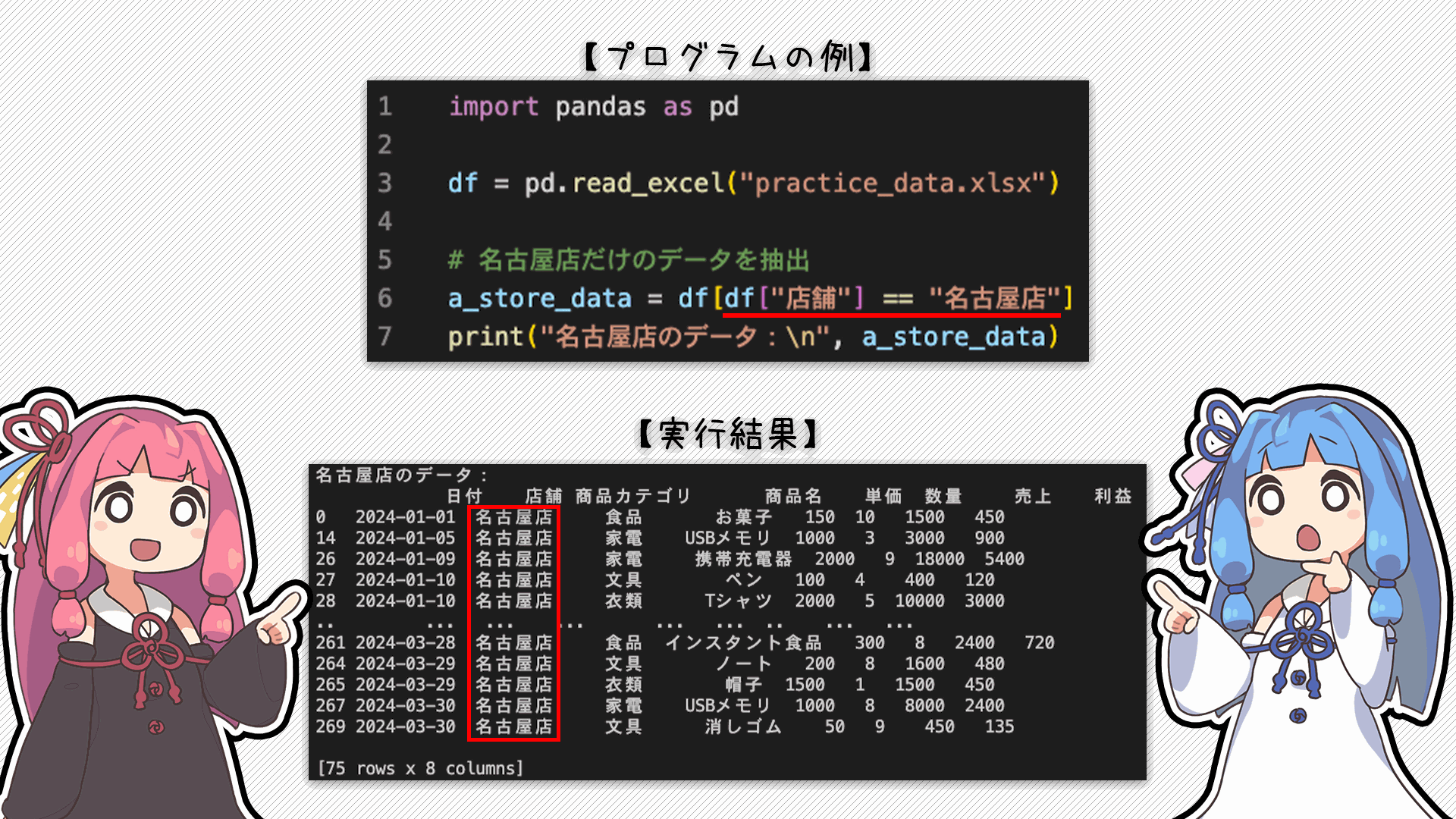
配列型とか辞書型で「[]」の中にインデックス番号とかキーを指定するけど、DataFrame型では「[]」の中で取り出したい条件を指定するって感じなんだね
そうだね!だから他の例として、「売上が1000以上のデータ」を取り出したい場合はこんな感じになるよ
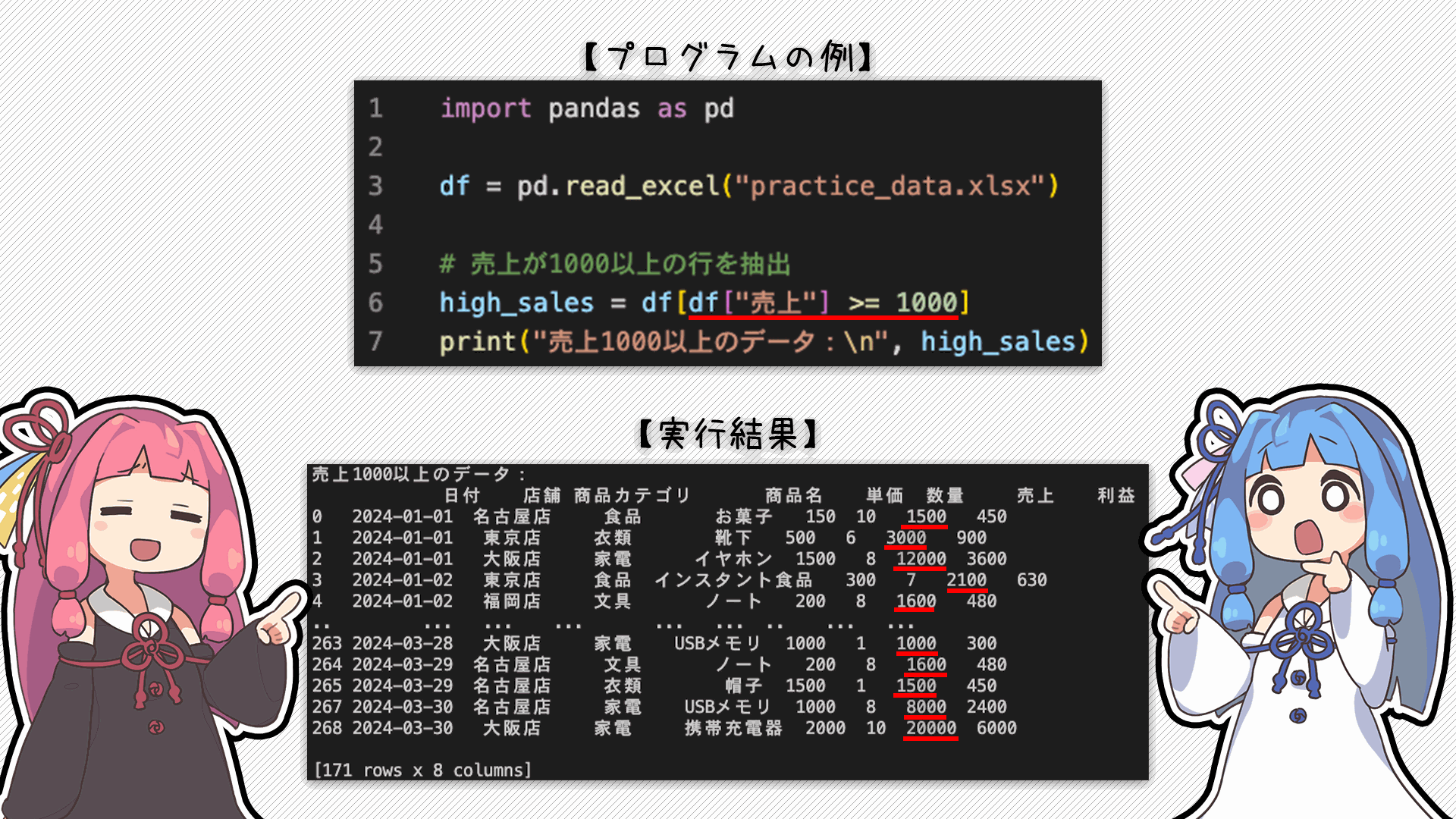
分かってしまえばシンプルな形なんだね!
次は、指定した項目の共通部分でグループ化して、そのグループごとの指定項目の合計値を計算する方法だよ

これは「店舗」でグループ化して「売上」を合計してるんだね!
それを1行で出来るのは凄いかも!
最後は、新しい項目を増やす方法だよ!
今回は「利益率」っていう項目を追加してるよ
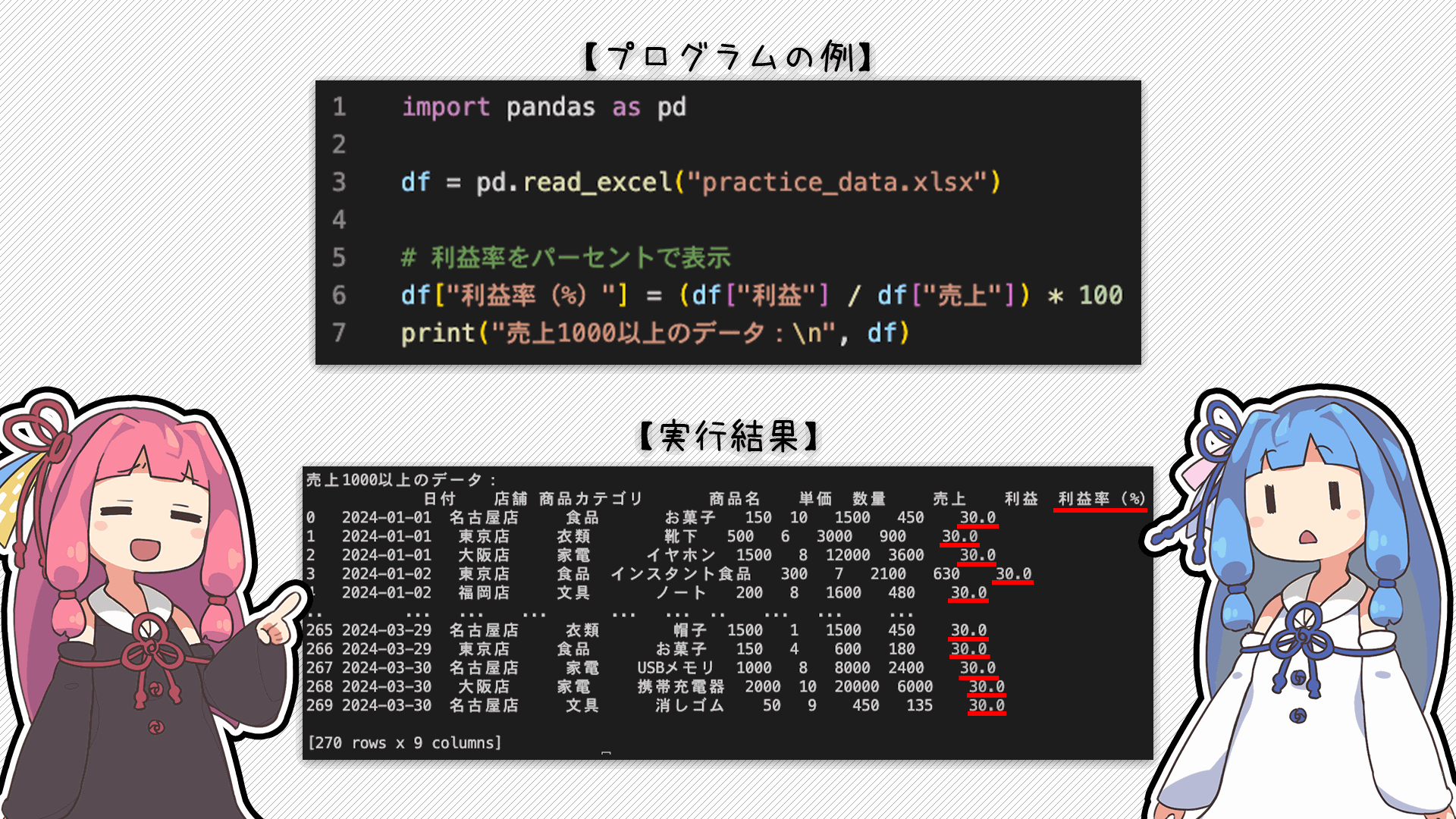
列の最後に「利益率」が追加されてる!
新しい項目が増えるだけじゃなくて全部の行に対してその項目のデータが追加されるのが良いね!
他にも便利な機能はあるんだけど、全部紹介するとキリがないから自分がやりたいことに合わせてネットで調べてみようね
分かった!そうする!!
今回も最後に、Pandasで読み込めるファイルと読み込み方の一覧と、よく使う機能の一覧を載せておくね!
| 関数 | 対応形式 | 拡張子・備考 |
|---|---|---|
pd.read_csv() | CSVファイル | .csv |
pd.read_table() | 区切り付きテキスト | .txt など |
pd.read_excel() | Excelファイル | .xls, .xlsx |
pd.read_json() | JSON形式 | .json |
pd.read_html() | HTMLのテーブル | .html |
pd.read_sql() | SQLクエリや接続 | データベース |
pd.read_clipboard() | クリップボード | テキスト(表形式) |
| 構文 | 機能 | 例 |
|---|---|---|
df.head() | 先頭の数行を表示 | df.head() |
df.describe() | 統計量の表示 | df.describe() |
df["列名"] | 列の抽出 | df["name"] |
df.loc[行] | 行の抽出(ラベル指定) | df.loc[0] |
df.iloc[行番号] | 行の抽出(番号指定) | df.iloc[3] |
df.sort_values("列名") | 並び替え | df.sort_values("score") |
df.groupby("列名") | グループ化と集計 | df.groupby("class").mean() |
df.isnull() | 欠損値の確認 | df.isnull().sum() |
df.dropna() | 欠損値の削除 | df.dropna() |
df.fillna(値) | 欠損値の補完 | df.fillna(0) |
df.merge(df2) | データフレームの結合(横方向) | df.merge(df2, on="id") |
pd.concat([df1, df2]) | データフレームの結合(縦または横) | pd.concat([df1, df2], axis=0) |