
推しアニメのグッズの予約受付があるの知らなかったからタイミング逃しちゃってすごくショックなんだけど...

あらま、それは残念だったねぇ
見逃しがないように公式サイトの最新情報を細かくチェックするのは大変だし、見てない時に限ってこういうことがあるんだよ
じゃあ、サイトの最新情報のチェックをPythonにしてもらったらどうかな?
え!?Pythonってパソコンの中だけじゃなくてサイトの情報を取ることもできるの!?
そうなんだよねー
ちなみにサイトの情報を取得することを「スクレイピング」って言うよ!

それはぜひ教えてほしい!
じゃあまずは、スクレイピングするための外部ライブラリを2つ紹介するよ!


(...なんか美味しそうな名前)
「requests」はサイトの情報を取得するんだけどデータ型は文字列の状態だから、その後に「BeautifulSoup」を使って情報を解析して操作できるようにするんだ
急に外部ライブラリが2種類も出てきたけど覚えられるかな...
「requests」はシンプルだから大丈夫
基本的にはこの書き方を知っていれば良いよ!
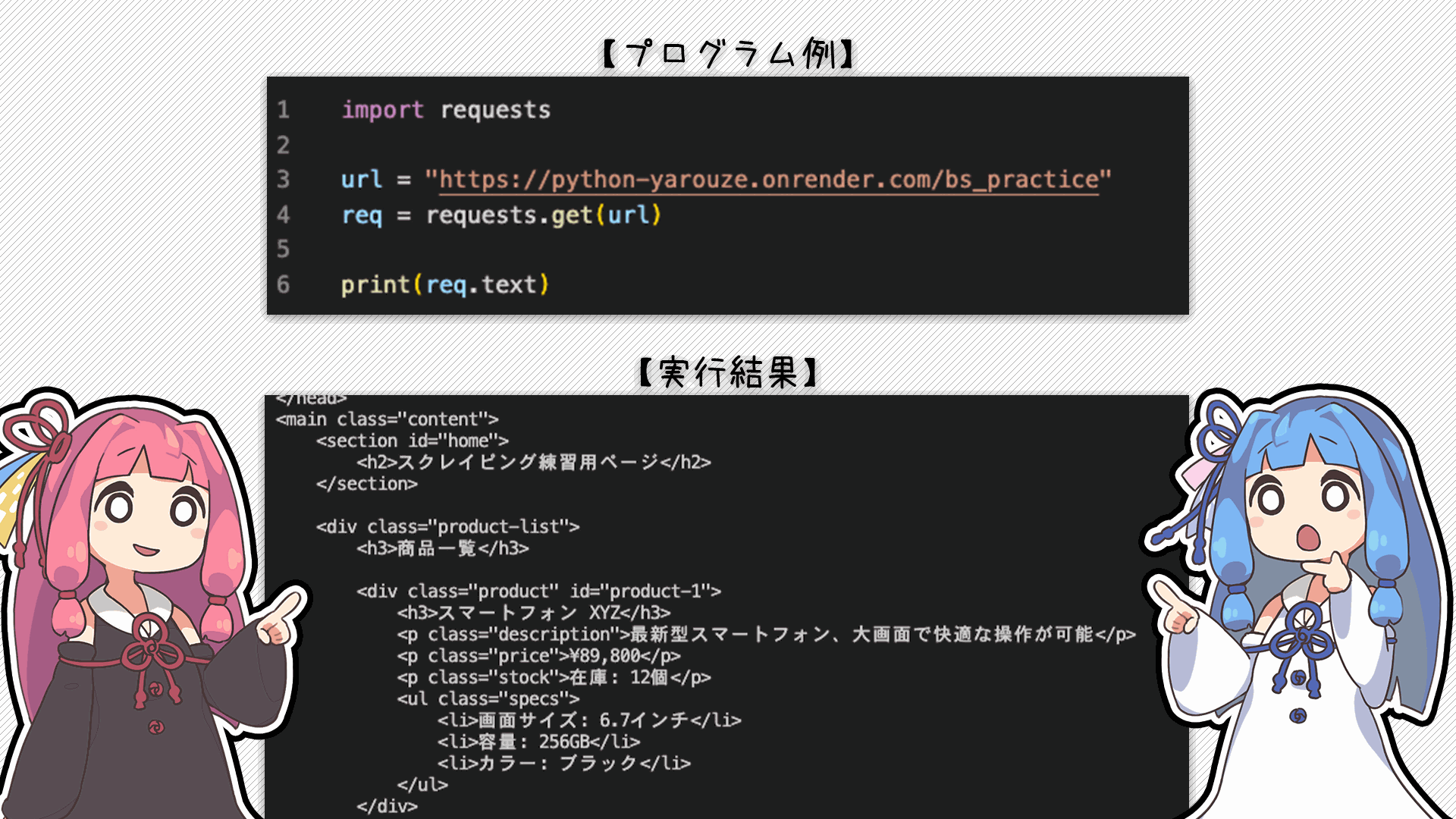
これだけでサイトの情報が取れるんだね!!
簡単でしょ?ちなみに取得しているのはスクレイピング練習用ページを構成している「htmlファイル」の中身になっているよ
だけど、確かにこのままじゃ中身がよく分からないね
そこで使うのが「BeautifulSoup」だよ
実際に使ってるところを見てみようか
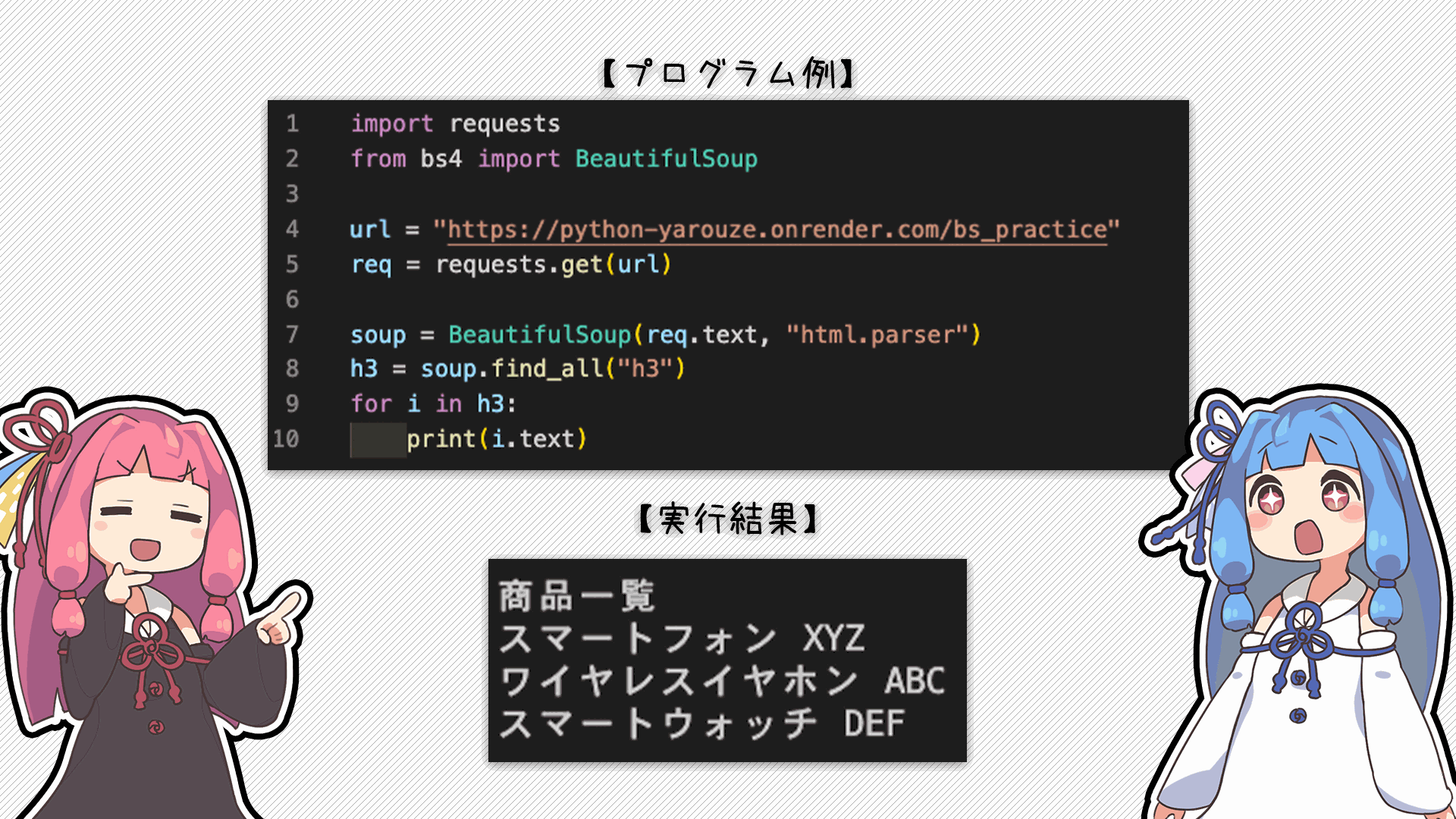
おお!プログラムの方はまだよく分からないけど綺麗にデータが取れてる!!
じゃあ少しずつ段階を踏んでデータの取得方法を説明しようかな
よろしくお願いします!!
...っとその前に、HTMLの構成について簡単に紹介しておくね
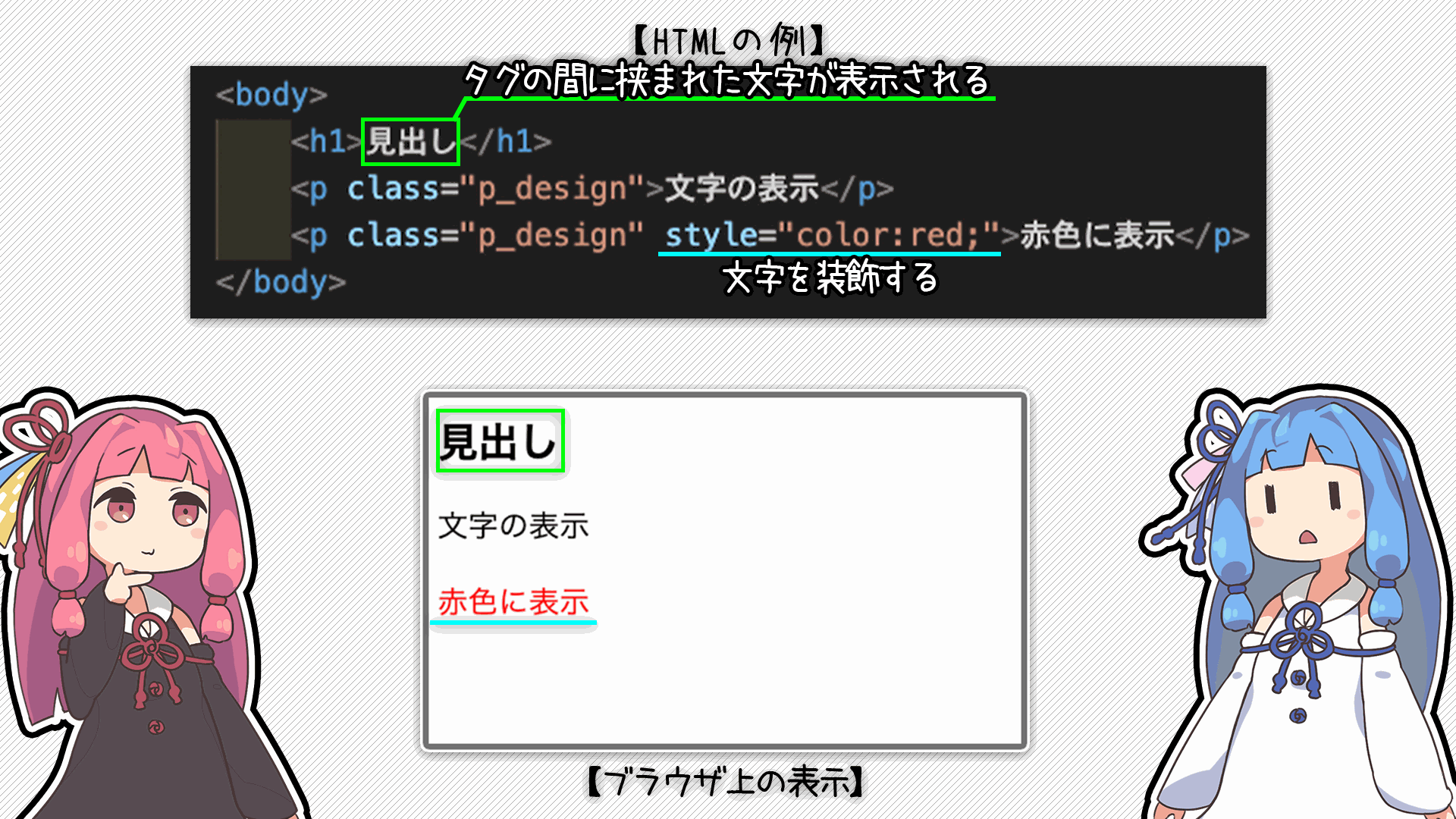
ちなみに「タグ」は「<p></p>」とか「<h1></h1>」とかのことね!
HTMLはタグに囲まれた部分がサイト上に表示されて、タグの中にデザインの情報とかを入れてるって感じだね
それだけ分かっていればスクレイピングは多分大丈夫かな!
もし見ているサイトのHTMLの構成を見たい時は次のようにすると確認できるよ!
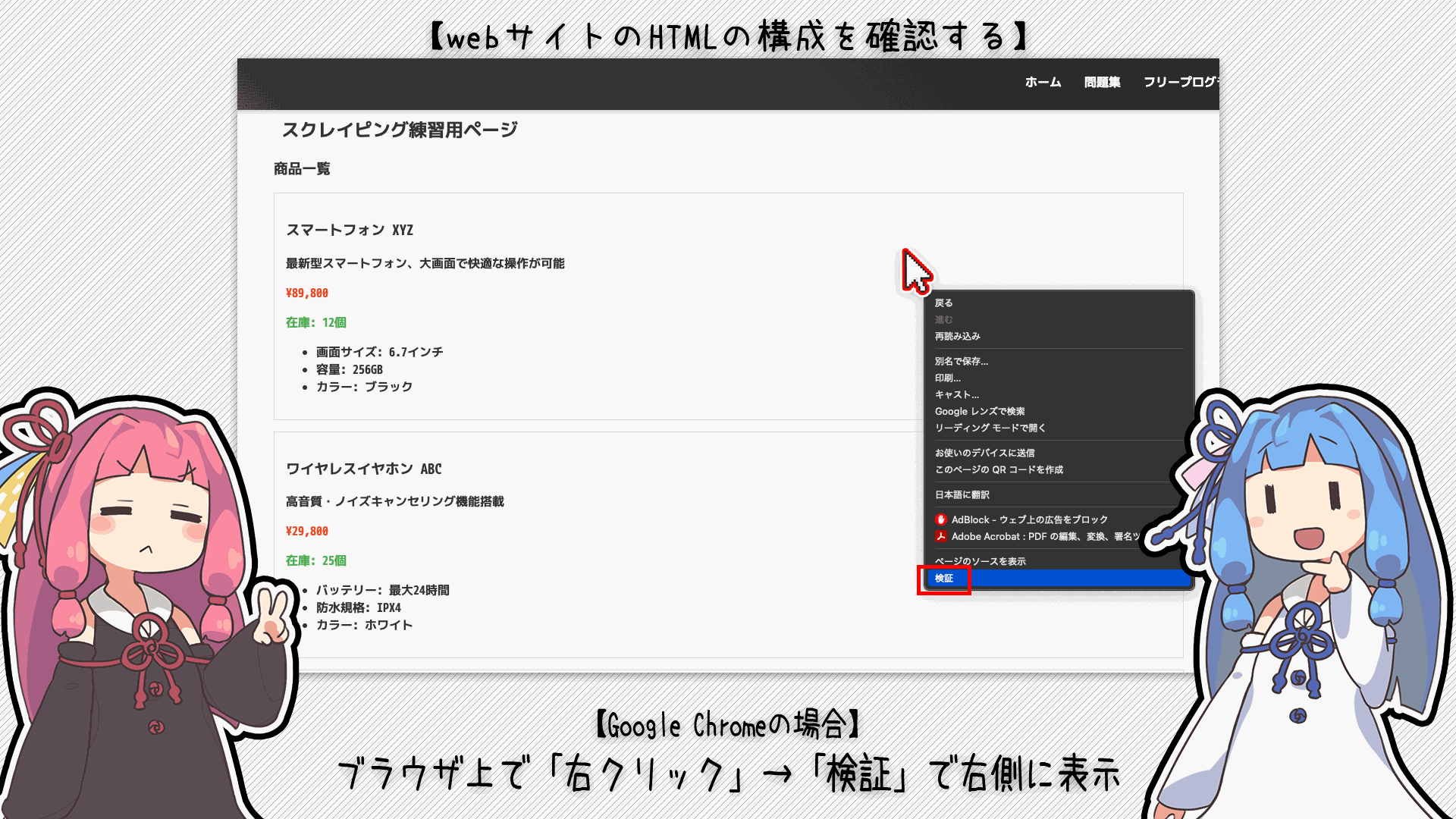
いつも使ってたブラウザにそんな機能があったのか...!!
さて、そしたら改めて...
まず最初はhtmlの中から取得したい情報を持っているタグを指定するよ
最初に一致したタグだけで良い場合は「.find()」で、一致したタグを全部取得したい場合は「.find_all()」を使うよ

指定する時はタグの名前を指定するか、タグの中に入ってる情報で指定するって感じなんだね
次にタグの中から欲しいデータを取得する方法を説明するね
タグで囲まれたテキストを取得したい場合は「.text」で、タグの中の情報を取得したい場合は「.get('〇〇')」を使うんだ
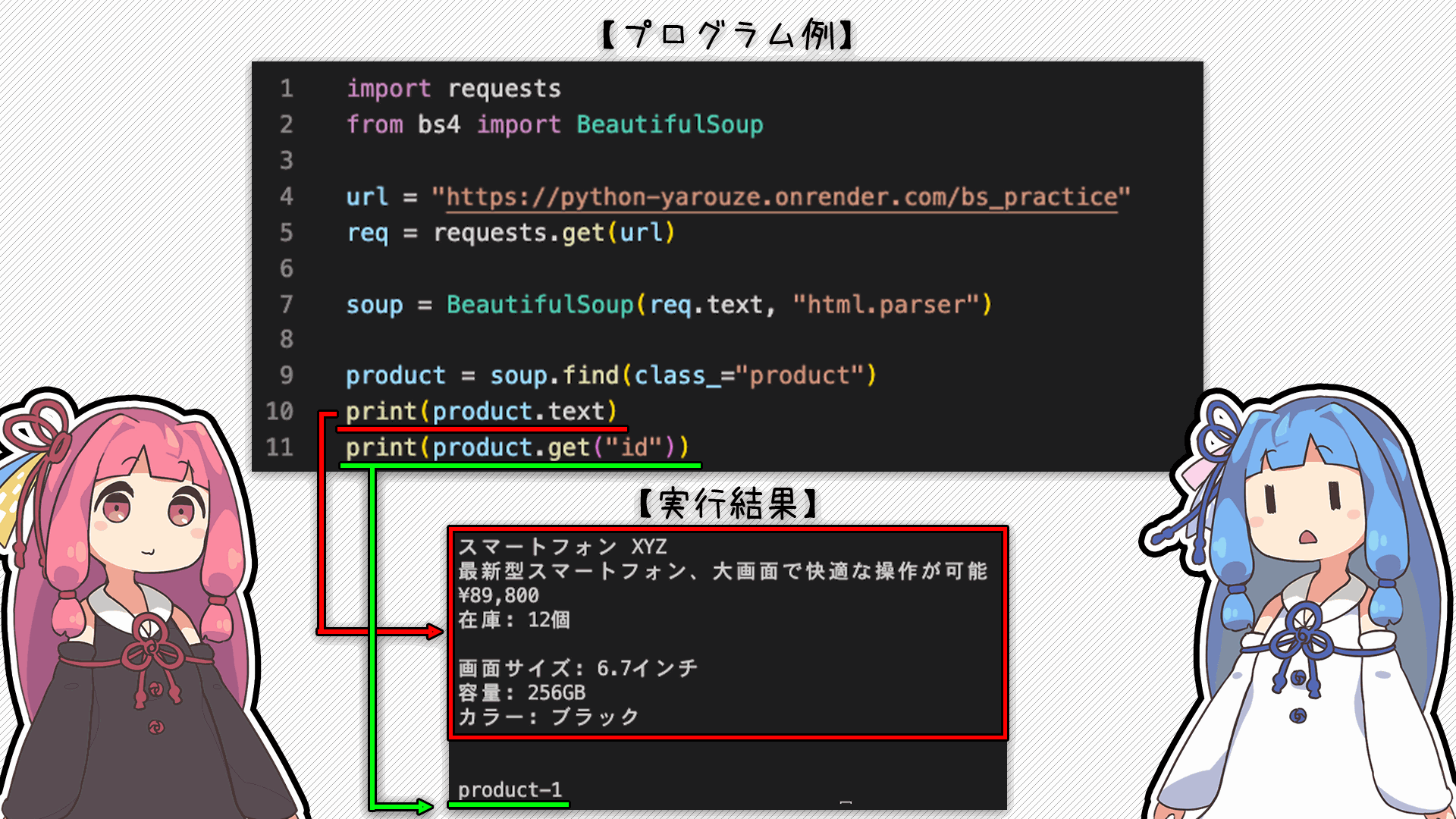
うーん...
それぞれがどこのどういう情報が取れるのかがいまいちピンとこない...
そしたら、こうすると分かりやすいかな?

なんとなく分かった!
まぁやってることは結構ワンパターンだから、使ってるうちに慣れてくると思うよ!
最後に一覧表を置いておくから、また忘れたら確認してみてね!
| 構文 | 説明 | 例(soup = BeautifulSoup(html, "html.parser")) |
|---|---|---|
soup.title | HTMLの<title>タグを取得 | print(soup.title) |
soup.find(tag) | 最初に一致したタグを取得 | data = soup.find("h1") |
soup.find_all(tag) | 一致するタグを全て取得 | datas = soup.find_all("p") |
.text | タグ内のテキストだけを取得 | data.text |
.get("属性") | 属性の値を取得 | data.get("href") |
.name | タグの名前を取得 | print(data.name) |
ちなみに一覧の例にも書いてるけど、「class="〇〇"」を使って指定する場合は「.find(class_="〇〇")」って感じで「_」がつくから気をつけてね
はーい!